手把手搭建本地 RAG:从零开始用 Ollama 和 ChromaDB
学会安装 Ollama、ChromaDB,跑通本地知识库问答,避免 AI 幻觉引用。
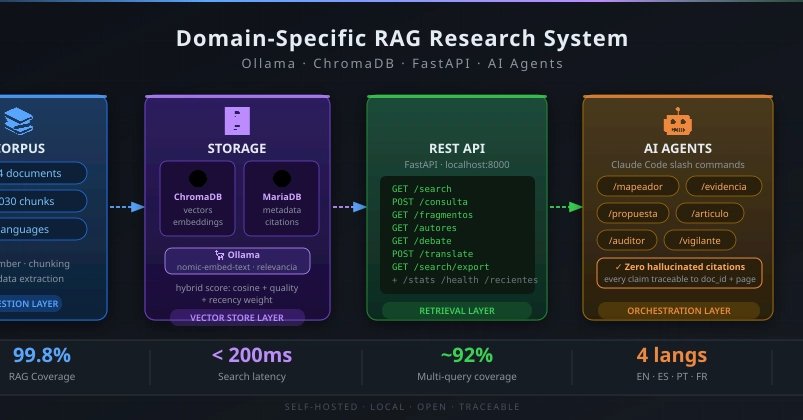
准备环境:你需要装什么?
在开始之前,先理解两个核心工具:Ollama(一个让你在本地运行大语言模型的工具,就像在电脑上装了一个 AI 大脑)和 ChromaDB(一个专门存储和搜索“知识片段”的数据库,能快速找到相关段落)。
- 下载并安装 Ollama:访问 ollama.com,选择你的操作系统(Windows、macOS 或 Linux),下载后双击安装。
- 打开终端(Windows 用 PowerShell,Mac/Linux 用 Terminal),运行
ollama pull llama3.2(下载一个轻量模型,约 2GB)。 - 安装 Python 3.8 以上版本(如果已有则跳过)。
- 在终端运行
pip install chromadb ollama fastapi uvicorn安装所需 Python 库。 - 在终端运行
chroma run --path ./my_knowledge,这会在当前目录下创建一个名为my_knowledge的文件夹来存放数据。 - 保持这个终端窗口打开(服务在后台运行)。
- 新建一个 Python 文件,比如
test_rag.py,写入以下代码: - 运行
python test_rag.py。如果输出AI 是人工智能的缩写...,说明安装成功! - 用 FastAPI 搭建一个网页接口,让用户通过浏览器提问。
- 把 PDF、网页等文档拆分成小段落(分块),存入 ChromaDB,构建你自己的知识库。
- 结合 Ollama 的对话能力,让 AI 根据搜索到的知识回答,避免幻觉引用。
常见坑:Ollama 安装后可能需要重启终端才能识别命令;如果下载模型慢,可以换国内镜像源。
安装并启动 ChromaDB
ChromaDB 就像你的知识仓库,你需要先创建它。
常见坑:如果端口被占用,可以加 --port 8001 指定其他端口。
第一次跑通:用 Python 添加并搜索知识
现在我们来测试整个系统是否正常工作。
import chromadb
from chromadb.utils import embedding_functions
# 连接 ChromaDB(默认端口 8000)
client = chromadb.HttpClient(host='localhost', port=8000)
# 创建或获取一个集合(类似数据库表)
collection = client.get_or_create_collection(
name='test_collection',
embedding_function=embedding_functions.OllamaEmbeddingFunction(
model_name='llama3.2'
)
)
# 添加一段知识
collection.add(
documents=['AI 是人工智能的缩写,指由机器模拟人类智能的技术。'],
ids=['doc1']
)
# 搜索
results = collection.query(query_texts=['什么是 AI?'], n_results=1)
print(results['documents'][0][0]) # 应该输出你添加的那段话
常见坑:如果报错 ModuleNotFoundError,检查是否用 pip list 确认所有包已安装;如果连接拒绝,确保 ChromaDB 服务在运行。
下一步可以做什么
你已经跑通了本地 RAG 系统!接下来可以:
记住:所有数据都在你的电脑上,隐私安全。现在开始动手吧!
内容来源
DEV Ollama
发布时间
2026-05-13 01:33