零基础入门:用Python实现AI模型效果评估
从安装Python和Jupyter开始,一步步教你用回归不连续设计(RDD)评估AI模型效果,小白也能跑通代码。
准备环境:装好Python和必备工具
首先,你需要安装Python(一种编程语言,用来写代码)和Jupyter Notebook(一个写代码的网页工具,方便一步步运行)。

- 去 python.org 下载Python 3.8以上版本,安装时记得勾选“Add Python to PATH”。
- 打开终端(Windows按Win+R输入cmd,Mac打开“终端”),运行
pip install jupyter pandas numpy matplotlib seaborn statsmodels,一次性安装所有需要的库。 - 常见坑:如果提示“pip不是命令”,说明Python没加到PATH,重装时勾上即可。
下载数据并打开Notebook
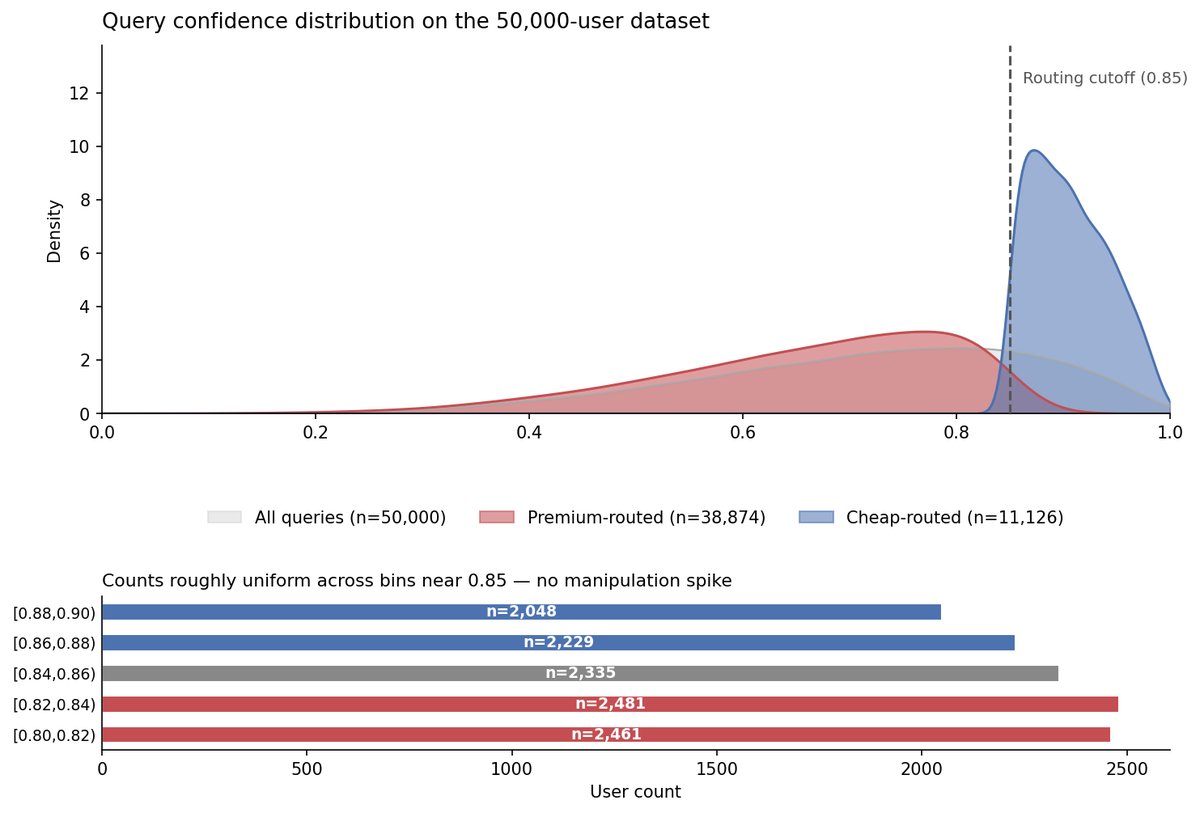
我们用一个模拟数据集,包含5万条用户查询记录,已经内置了真实效果(+6%)。
- 从原文提供的GitHub链接下载
synthetic_data.csv文件,放到一个文件夹里。 - 在终端进入该文件夹,输入
jupyter notebook,浏览器会自动打开。 - 点击“New” -> “Python 3”新建一个笔记本。
运行代码:评估模型效果
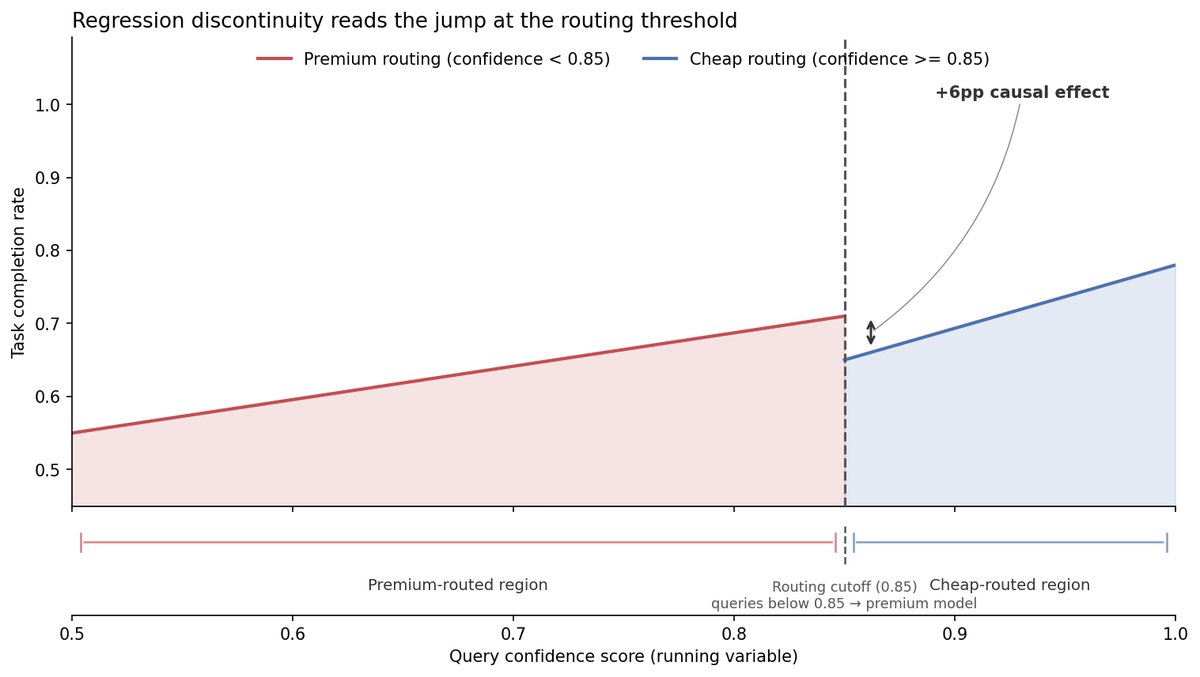
核心思路:AI系统会根据置信度分数(0到1之间的数字,表示模型对答案的自信程度)决定用哪个模型。低于0.85用高级模型,高于0.85用廉价模型。我们想知道高级模型是否值得。
- 在Notebook中粘贴以下代码并运行:
import pandas as pd
df = pd.read_csv('synthetic_data.csv')
print(df.head()) - 你会看到数据包含“confidence”(置信度)和“completed”(是否完成)等列。
- 接着运行回归不连续分析(一种统计方法,比较阈值附近的数据差异)的代码(见原文Notebook)。
- 常见坑:如果报错说缺少库,用pip安装对应的包即可。
验证结果:看看效果是否显著
最后会生成一个图表和数字,显示在置信度0.85处,完成率有一个跳跃,那就是高级模型带来的效果。
- 如果跳跃大约是6%,说明分析成功。
- 你可以调整带宽(分析范围)看结果是否稳定。
下一步:尝试用自己的数据,或者修改阈值(比如改成0.9)重新运行。
内容来源
freeCodeCamp
发布时间
2026-05-11 01:30