AI入门:手把手教你用OCR+LLM提取PDF表格
学会安装OCR Wizard API,用混合方法提取PDF表格,零基础也能跑通第一个AI项目。
你是不是经常需要从PDF发票或合同里提取表格数据?手动复制粘贴太慢,而且容易出错。别担心,2026年有个新方法:用OCR(光学字符识别)加LLM(大语言模型)组合,既能准确读出文字,又能智能整理成表格。这篇教程带你从零开始,一步步装好工具、跑通代码。
准备环境:你需要装什么
- Python:一种编程语言,用来运行我们的脚本。去 python.org 下载3.10以上版本,安装时记得勾选“Add Python to PATH”。
- OCR Wizard API:一个在线服务,能把图片里的文字识别出来。去 ai-engine.net 注册账号,拿到API密钥(一串字符,用来验证身份)。
- OpenAI API密钥:用来调用大语言模型(比如GPT-4o)。去 platform.openai.com 注册并充值,拿到密钥。
- 代码编辑器:推荐VS Code,免费又好用。下载地址 code.visualstudio.com。
安装步骤:一步步来
- 打开终端(Windows按Win+R,输入cmd;Mac打开“终端”应用)。
- 创建一个新文件夹,比如
pdf_extract,然后进入:mkdir pdf_extract && cd pdf_extract。 - 安装必要的Python库:
pip install requests openai。这会在你的电脑上安装两个工具包,一个用来发网络请求,一个用来调用AI。 - 创建一个新文件,命名为
extract.py,用VS Code打开。 - 复制下面的代码进去(记得替换
YOUR_OCR_KEY和YOUR_OPENAI_KEY为你的真实密钥):
import requests
import openai
# 第一步:用OCR提取文字
ocr_response = requests.post(
"https://api.ai-engine.net/ocr",
files={"file": open("你的PDF文件路径.pdf", "rb")},
headers={"Authorization": "Bearer YOUR_OCR_KEY"}
)
text = ocr_response.json()["text"]
# 第二步:用LLM整理成表格
openai.api_key = "YOUR_OPENAI_KEY"
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个表格提取助手。根据用户提供的OCR文本,重建HTML表格,不要修改任何数字或代码。"},
{"role": "user", "content": f"请将以下文本整理成HTML表格:\n{text}"}
]
)
print(response.choices[0].message.content)验证是否成功:跑起来看看
- 在终端中运行:
python extract.py。 - 如果一切顺利,你会看到一串HTML代码,那就是你PDF里的表格。
- 常见坑:如果报错“No module named requests”,说明没安装成功,再运行一次
pip install requests。 - 如果API密钥无效,检查密钥是否复制完整,注意不要有多余空格。
下一步可以做什么
- 尝试更换不同的PDF文件,看看效果。
- 修改代码中的提示词(prompt),比如要求输出CSV格式。
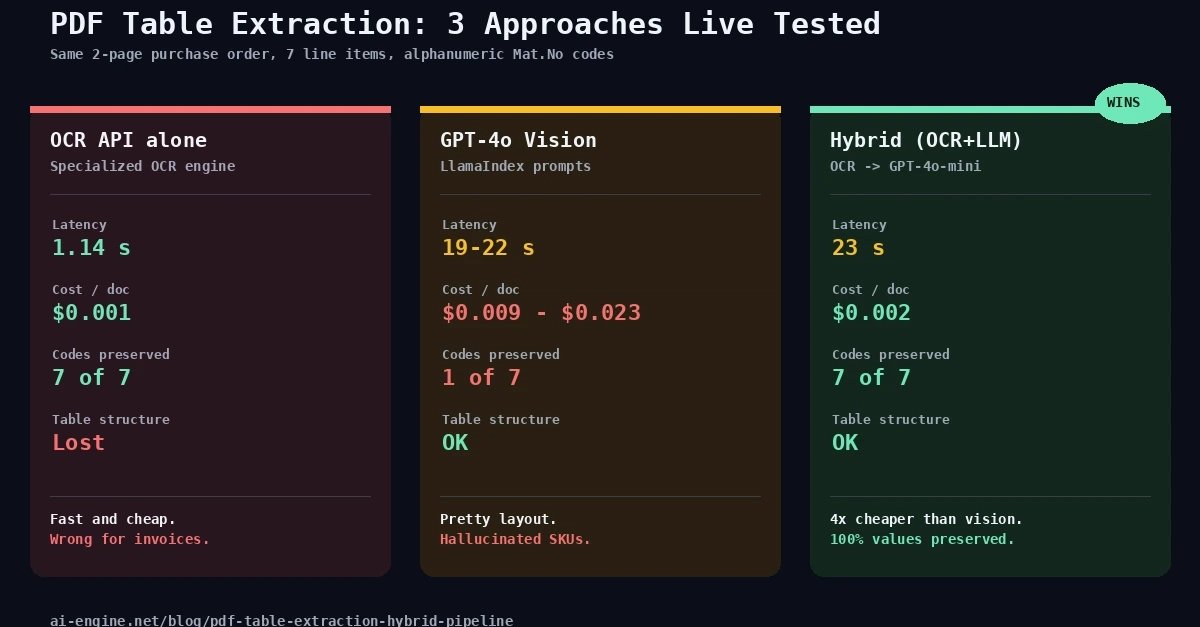
- 学习更多关于OCR和LLM的知识,比如为什么混合方法比纯视觉模型更准确:因为OCR逐字识别,不产生幻觉;LLM只负责排版,不篡改数据。
内容来源
DEV Machine Learning
发布时间
2026-05-31 01:36